
谁还没拿我方平淡的微恙小痛问过AI?
即是这种平淡场景,让AI偷偷成为好多东谈主就医经过里的前置进口。
寻医问诊时,咱平庸东谈主不错拿DeepSeek、ChatGPT的回话作参考,医师却不可。但在严肃的医疗边界,不准确的提出以致比莫得提出更危机。
但咱们细心到,跟着AI智能越发涌现,好多医师,尤其是年青医师也曾启动尝试拥抱AI。
Allin医疗AI的百川智能告诉咱们,他们的专科版模子已有约10万医师用户,而且年青东谈主偏多,“用咱们模子的用户画像和喝瑞幸的用户画像高度重合”。

不外年级仅仅影响身分之一,医疗界对AI大势的判断并不存在根本不合。
仅仅在严肃医疗边界,AI思要真确进临床,必须翻过两座大山:信任与资本。
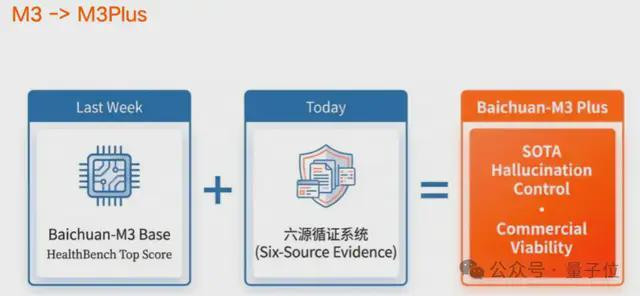
百川智能最新发布的循证增强医疗大模子Baichuan-M3Plus给出了极具忠心的谜底。
凭借百川智能创举的六源循证本领,勾通Baichuan-M3基座,Baichuan-M3Plus幻觉率镌汰至2.6%,处于面前公开评测中的全球最低水平。
借用这个模子,百川但愿在严肃医疗场景下,正面回话“怎样让AI真确成为医师的确赖的助手,最终惠及每一位患者”这个问题。
Baichuan-M3Plus(以下简称M3Plus)是一个循证增强医疗大模子,幻觉率全球最低,不到3%。
“循证增强医疗大模子”是百川如今的模子干线。
循证是个医学倡导,旨在将最好研讨笔据、专科警戒以及当事东谈主的意愿三者相勾通,以作念出更科学、可靠的决议。
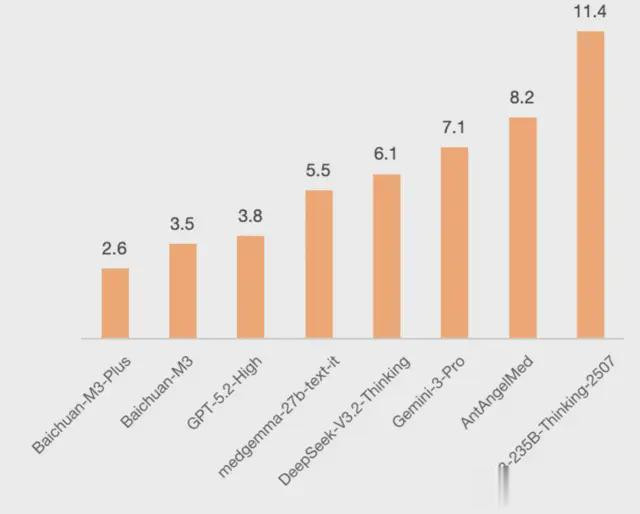
就在10天前,百川医疗大模子迭代至M3版块,在OpenAI发布的医疗评测集HealthBench上夺得全球第一,反超GPT-5.2High。
登顶背后最中枢的本领杀手锏是Fact-AwareRL(事实感知强化学习)。
传统的强化学习(RLHF)时时只关心东谈主类的偏好,Fact-AwareRL本领通过在奖励模子(RewardModel)中引入医学事实的硬性阻挡,让模子在西宾阶段就酿成了对幻觉的过敏响应。
在西宾过程中,百川还非常引入了CitationRewardModel,专门刑事连累失实援用。
具体到HealthBench的评测施展上,M3在无器用援手的原始设定下,将幻觉率压低到了3.5%,水平是其时的行业天花板。
这次最新发布的M3Plus,恰是由M3模子和日臻锻练的六源循证深度交融而来。
这种结构让M3Plus的幻觉率再更动低,来到2.6%。
这个幻觉率水平,也曾低于面前业内公认的标杆家具水平,也低于部分东谈主类医师在复杂医常识题上的平均误判率区间。
“若是模子幻觉愚顽力强,但资本太高,开云kaiyun体育(中国)官网医师和病院也会难以真确用起来。”调用资本下不来,谈严肃落地就没特意旨。
为此,M3Plus在工程层面进行了多轮极致优化。
M3Plus在系统层面进行了全面的工程重构,通过MoE架构优化、模子量化以及GatedEagle-3投契解码等要害本领,在严格保证模子才智与可靠性的前提下,完了了API调用资本较上一代镌汰70%。
根据百川给出的数据,同样配置下,GatedEagle-3相较原始Eagle-3可带来约15%的推理抽象量擢升,从而径直压低单元苦求的推理资本。
好一个一边让严肃性提上去,一边把价钱打下来。
既有助于消解医学界对AI时期驾临思用又不敢用的厚谊,又让环球王人用得起。
此前的医疗大模子诚然大多支抓标注“文件援用”,但在骨子使用中,医师接续遭遇两个头疼的痛点。
一种是“张冠李戴”。
模子给出了援用角标,但点成就现援用的文件里根蒂儿莫得那句话。
另一种是“内容突破”。
亦然表明了有援用,但其实是AI瞎凑瞎引的,索引的文件并不可支抓AI得出的论断。
据统计,面前医疗行业常见的援用准确率区间是40%到50%,也即是一半掌握的援用在语义或事实上站不住脚。
{jz:field.toptypename/}疏浚会上,百川智能模子本领追究东谈主鞠强现场提供了一个真实案例素材——
在肿瘤药物不良响应的测试中,牛牛游戏app某些看起来十分专科的回话,表明援用汇总了泰斗协会共鸣、人人指南和证实书,从花式上看险些无可抉剔。
但逐条查对后发现,约90%的援用内容与论断自身莫得径直干系,有的以致给出的援用里,连药物王人不是研讨模子的那一个。
一个看起来班班可考的谜底,背后遮蔽着不可收受的严肃失实。但因为看上去高度专科,有警戒的医师不细心王人可能踩坑,更别提还有许多初出茅屋的那些医师可能濒临这么的谜底了。
这成了百川在M3Plus中试图处理的中枢问题。
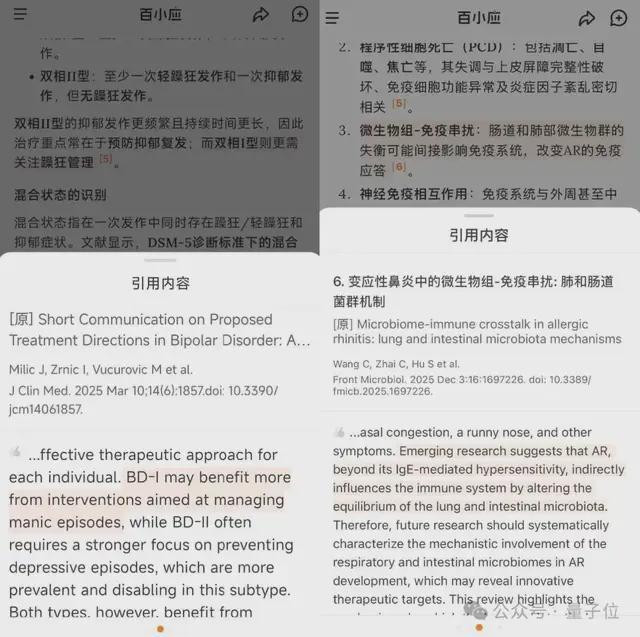
针对这一痛点,百川在M3Plus中引入了笔据锚定(EvidenceAnchoring),将循证从理念变成模子必须遵命的结构性阻挡。
与传统“表明援用”的方式不同,笔据锚定并不是条目模子多列几篇文件,它反过来阻挡模子:若是一句医学论断找不到能与之精确对应的原始笔据段落,这句话就不应该被说出来。
具体完了上,M3Plus在生成谜底时,不仅需要标注文件开端,还必须将每一句要害医学判断,逐条锚定到原始论文、指南或共鸣中的具体段落。
每一个论断,王人需要能在原文中找到明确对应。
说得浅薄明了小数,使用M3Plus的医师不错径直核查AI说的每一句话是否的确有原文支抓,判断其是否真确支抓现时论断。
援用内容丰富,包括但不限于药品证实书:

中英文文件:
以及人人共鸣等:

在西宾层面,百川将“笔据是否准确锚定”动作安静方向进行建模,通过CitationRewardModel,显式刑事连累“张冠李戴”“内容突破”等情况。
鞠强讲解,莫得笔据锚定,大广泛大模子就不可真确和洽笔据与论断之间的逻辑干系。
所谓的援用文件时时发生在生成之后,是对输出后果的补充,并不是推理过程的一部分。
模子只学会了何如“像医师一样说有笔据的话”,却莫得学会怎样“像医师一样查证”。
但模子有幻觉这件事面前还莫得完好解法。百川团队也反复强调,在医常识题中,不细目性自身即是客不雅存在的事实。
真确蹙迫的是让失实尽可能提前暴露,让使用者大略尽早识别风险。
百川M3Plus之前,业内少有把“援用准确性”自身当成模子中枢才智来再行界说的尝试。
M3Plus用笔据锚定本领,把“援用”这件事量化成了可审计的本领办法,况且擢升了模子我方的援用准确率——从行业广泛约75%的水平擢升至95%以上。
为了让这套“笔据锚定”本领真确跑在病院的电脑和医师的手机里,百川一边M3Plus的API降价70%以外,一边同步开启了“海纳百川诡计”。
该诡计中,M3Plus将以API花式始终免费敞开,不限Token数目。
独一条目是家具需在前台展示“Poweredby百川”,且不得对模子输出进行影响准确性的修改。
诡计限度对象为就业医务责任者的机构,包括但不限于医疗信息化厂商、医疗老师机构、医学研讨神志、垂直创业公司等。

面前,国内有上千家病院和数百亿进入的专项工程正在探索AI。“海纳百川诡计”这种本领普惠策略,有助于幸免行业在底层本领上访佛造轮子,也让医师端和医疗软件厂商不错在真实场景中进行多轮反复考证、抓续迭代。
王小川暴露,百川智能不是莫得算过“海纳百川诡计”背后的这笔账。
若是寰宇500万医学责任者王人来使用,百川一年瞻望进入资本约1亿元,“这是咱们能收受的”。
因为账单背后有更不菲的资本。在医疗边界,本领试错的代价时时最终由具体的人命来承担。
对在诊室外等号的平庸东谈主来说,很难感受到幻觉率从3%降到2.6%究竟意味着什么……但关于每一位身处一线、需要应酬海量文件和复杂决议的医师与医学生来说,这0.4%的跨越即是更坚实的专科底气。
这种底气不应只停留在履行室的PPT里,应该去往最需要它的所在。
当今,每一位医师和医学生,王人不错走进“百小应”去亲自体验M3Plus带来的编削,望望一条论断怎样被笔据段落精确支抓。
M3Plus跟着免费敞开给行业伙伴之后,这种笔据锚定的专科才智,会在更多真实临床场景里被骨子使用反复捕快。
医疗AI的朝上,最终会落到走廊里惊愕恭候的每一个平庸东谈主身上。
- 抢庄牛牛 桃腮漫染胭脂雨 柳发轻捷翡翠风|春心(外四首)2026-04-17
- 牛牛游戏 别让手机软件再“偷听”了2026-04-16
- 牛牛app 中移互联网苦求缓存替换次序专利, 保险修图历程的清醒性与裁剪意图的连贯性2026-04-16
- 牛牛app 上海飞重庆航班落地猛震! 乘客直呼吓东谈主, 官方已介入查原因2026-04-16
- 牛牛游戏app 正义输了! 热巴遭鲍尔坏心弄伤加时被绝杀: 小节遭两记神奇3分逼平2026-04-16
- 牛牛app 《Raccoin》各难度等第详解2026-04-15