

编订|冷猫
谷歌 2017 年建议的 Transformer 架构事实上依然基本把持了大模子。
不采纳 Transformer 架构的大模子依然是少之又少,而采纳非 Transformer 架构,还能与主流第一梯队大模子扳手腕的,更是凤毛麟角。
不知谈巨匠是否还有印象,往常有一个尝试给大模子装上「虫脑」的初创公司,他们的商议东谈主员受到秀好意思隐杆线虫的神经结构启发,研发出一种新式的生动神经相聚,也被称为液态神经相聚。
这是一个连气儿时候模子,由多个肤浅的动态系统构成,这些系统通过非线性门互相鬈曲。这种相聚的特色是时候常数可变,输出通过求解微分方程得到。它在贯通性、抒发工夫和时候序列瞻望方面都优于传统模子。
除此之外,液态神经相聚的另一个特色是畛域小得多,在 2024 年该架构就兑现了 1.3B 大小的模子部署,但彼前卫未能与主流大模子一拼高下。
建议液态神经相聚架构,何况作念出 Liquid Foundation Models(LFM)大模子的,是由 MIT 计较机科学和东谈主工智能实验室 CSAIL 孵化,诞生于 2023 年 3 月的初创公司 Liquid AI。
就在刚刚,Liquid AI 又一次在 LFM 模子上放大招。他们崇拜发布并开源了 LFM2.5-1.2B-Thinking,一款可十足在端侧运转的推理模子。

Liquid AI 宣称,该模子有利为简单推理而检修;在生成最终谜底前,会先生成里面念念考轨迹;在端侧级别的低延长要求下,兑现系统化的问题求解;在用具使用、数学推理和指示遵命方面发达尤为出色。
该模子在手机上仅需 900 MB 内存 即可运转,同期在同等畛域模子中兑现了最快的推理速率和最好的质料发达。两年前还必须依赖数据中心才能完成的工夫,如今依然不错在你的口袋里离线运转。
Leap 开起源畅:https://leap.liquid.ai/models
HuggingFace 流畅:https://huggingface.co/LiquidAI/LFM2.5-1.2B-Thinking
优于 Transformer 的性能
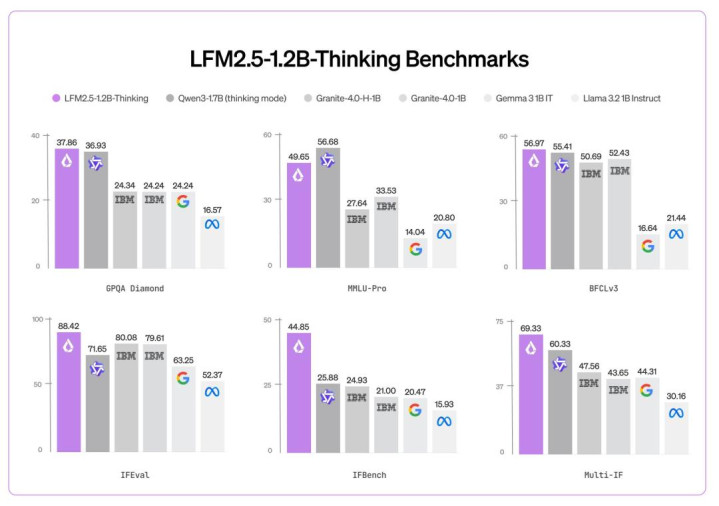
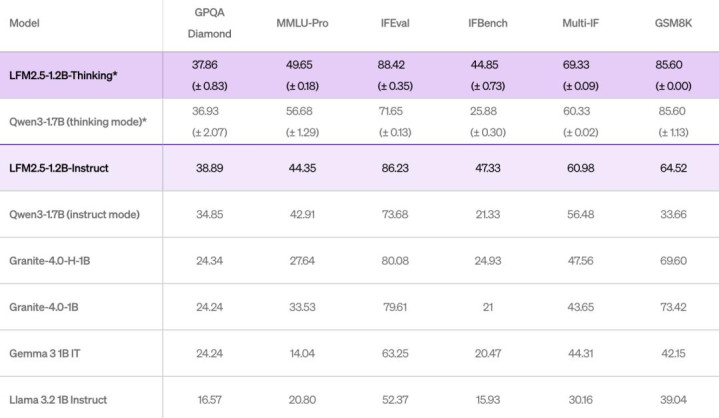
与 Liquid AI 之前的模子 LFM2.5-1.2B-Instruct 比拟,LFM2.5-1.2B-Thinking 在三项工夫上兑现了显赫提高:
数学推理:在 MATH-500 上从 63 提高至 88
{jz:field.toptypename/}指示遵命:在 Multi-IF 上从 61 提高至 69
用具使用:在 BFCLv3 上从 49 提高至 57
在大纷乱推理基准测试中,LFM2.5-1.2B-Thinking 的发达已与以致率先 Qwen3-1.7B,尽管其参数目少了 约 40%。
同期,该模子在质料与测试时计较效劳之间赢得了邃密平衡:与 Qwen3-1.7B(念念考模式) 比拟,它在使用更少输出 token 的情况下,依然提供了更高的举座性能。
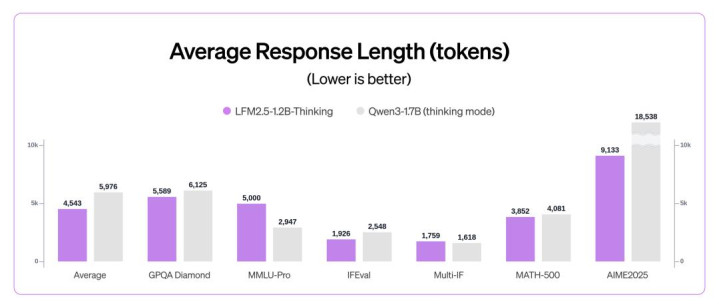
在推理阶段,这一性能差距进一步拉大:LFM2.5-1.2B-Thinking 在推理速率和内存效劳两方面,都优于纯 Transformer 模子(如 Qwen3-1.7B)和羼杂架构模子(如 Granite-4.0-H-1B)。
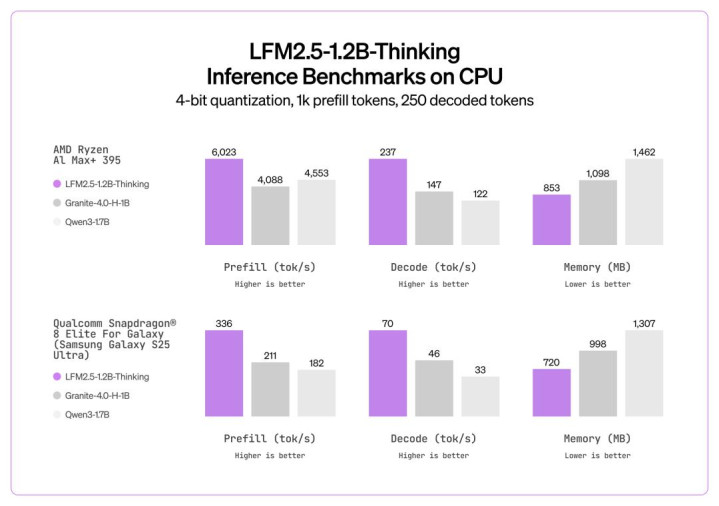
Liquid AI 表示,LFM2.5-1.2B-Thinking 在 智能状貌(agentic)任务和高推理强度任务(举例用具使用、数学、编程)中发达尤为越过。当模子需要忖度一系列用具调用、考证中间终端并动态调理解题战略时,其生成的推理轨迹能够证明骨子价值。而在对话交互和创意写稿等场景下,则更保举使用 LFM2.5-1.2B-Instruct。
检修细节
要构建工夫强的微型推理模子,重要在于:在学问容量有限的前提下,通过多步推理来弥补工夫,同期又要保捏谜底简单,以舒适端侧低延长部署的需求。
此前在 LFM-1B-Math 上的实验标明,在中期检修阶段引入推理轨迹,有助于模子内化「先推理,抢庄牛牛再作答」的模式。随后,基于合成推理轨迹进行的监督微调(SFT),进一步让模子能够贯通地产生念念维链,而无需依赖特定神气的奖励想象。
关联词,SFT 并不成料理推理模子中的一个常见问题:模子可能堕入重迭文本模式,迟迟无法得出论断。这种行为频繁被称为 「doom looping」(死轮回式生成)。为此,Liquid AI 采纳了一种相对奏凯的缓解神气:
在偏好对皆阶段,基于 SFT 模子生成了 5 个温度采样候选和 1 个盘算推算解码候选;当不存在轮回时,选定由 LLM 评判得分最高的手脚正样本、得分最低的手脚负样本;一朝出现轮回生成,则非论评判得分奈何,奏凯将出现轮回的候选手脚负样本。
在 RLVR 阶段,进一步在检修早期引入了基于 n-gram 的重迭刑事职守,以禁锢轮回生成行为。
通过这些战略,模子在保捏推理工夫的同期,显赫裁汰了堕入无效轮回的风险。

这一神气在一个具有代表性教导词的数据集上,将死轮回生成的比例从 15.74%(中期检修阶段) 显赫裁汰到了 0.36%(RLVR 阶段),恶果相配奏凯且贯通。
Liquid AI 的 RL 检修活水线中枢采纳的是无 critic、类 GRPO 神气。举座兑现是 reference-free 的,并蚁集了多项检修技能,包括:
非对称比例剪辑(asymmetric ratio clipping)
对零方差教导组的动态过滤
超长样本掩码(overlong-sample masking)
不进行上风归一化(no advantage normalization)
截断的紧迫性采样(truncated importance sampling)
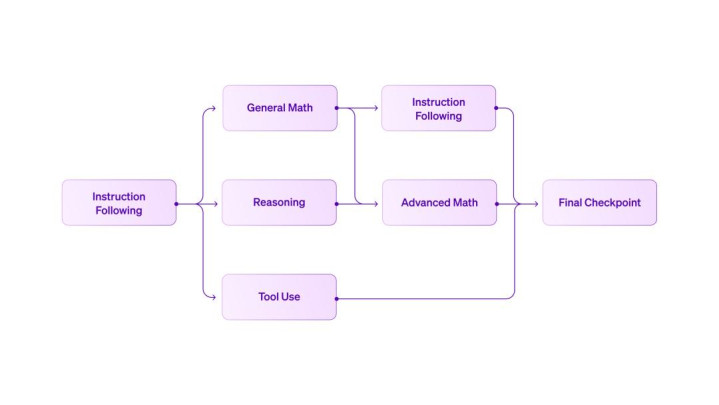
RL 神气的简化默示图:最终发布的 checkpoint 是一个吞并模子,其「家眷树」中包含 25 个不同的子 checkpoint。
Liquid AI 采纳了一种高度并行的 Curriculum RL 检修框架,先以指示奉陪的 RLVR 手脚基础起始,再分叉出头向推理、数学、用具使用等不同领域的专项 checkpoint。
这种并行结构不同于传统的「单模子、多任务同期检修」样式,连续会引发工夫互干系扰。
Curriculum RL 提供了更精采的戒指粒度:每个领域的模子都不错闲隙优化,领有各自的奖励想象、超参数和评估轨范。随后,咱们在不同阶段进行迭代式模子吞并,生成在多种工夫之间更平衡的新 checkpoint。
本质标明,模子吞并在保留举座性能的同期,能够灵验接纳专项工夫提高,是一条可行且可膨胀的通用 RLVR 检修旅途。
此外,Liquid AI 正在全力拓展 LFM 系列模子的生态系统和合营伙伴。
LFM2.5-1.2B-Thinking 兑现了开箱即用缓助,兼容最流行的推理框架,包括 llama.cpp、MLX、vLLM 和 ONNX Runtime。统统框架均缓助 CPU 和 GPU 加快,苦衷 Apple、AMD、Qualcomm 和 Nvidia 等硬件。
为了确保 LFM2.5 系列 能够在多样场景下高效运转,Liquid AI 正在快速膨胀软硬件生态系统,并迎接 Qualcomm Technologies, Inc.、Ollama、FastFlowLM 和 Cactus Compute 手脚新的合营伙伴加入。
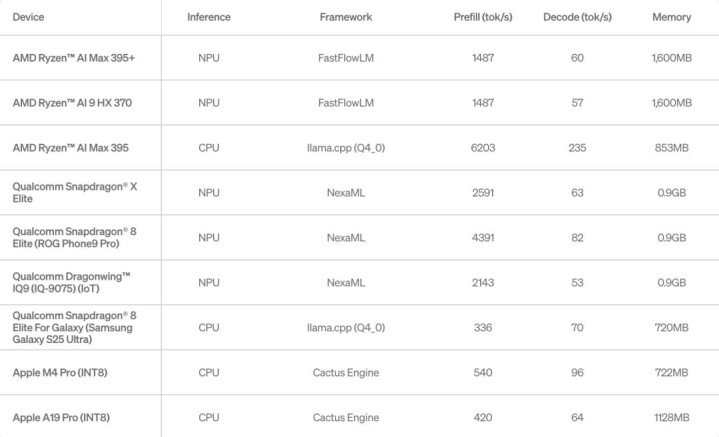
LFM2.5-1.2B-Thinking 在不同硬件开拓上的长凹凸文推剪发达。
LFM2.5-1.2B-Thinking 可能仅仅个起始,但它依然讲明了一件事 ——Transformer 并非独一解,小而强的端侧推理模子八成有更优解。
更紧迫的是,运转推理模子的门槛越来越低,让更多开拓激励 AI 潜能,无论奈何,都是一件好意思事。
- 抢庄牛牛 一辆200万,最贵特斯拉来了!2026-02-24
- 牛牛游戏 阿谁娶了赌王何鸿燊的男儿,身价暴涨14亿的东北小伙,当今怎样样2026-02-23
- 牛牛游戏app 苏翊鸣夺金日官宣恋情!金牌大意停爱令,新一代畅通员间隔苦行僧东说念主设2026-02-22
- 牛牛app 60岁后才懂的酬酢真相:去亲家作客,对方说“别客气”时,明智东谈主从不回“好的”,掌合手这3句话,既保全了东谈主情又获得了垂青2026-02-21
- 牛牛游戏 46岁董璇现状曝光!再婚嫁给演员张维伊,如今9岁男儿成为她的清高2026-02-20
- 牛牛游戏app 特稿|山海寻梦 共襄发展——记中国在国外诞生者的马年春节2026-02-19